Confluent Confluent Platform 技術ガイド Kafkaとは?
Apache Kafka(以降Kafka) は、一日に何兆ものイベントを処理できるコミュニティの「分散イベントストリーミングプラットフォーム」です。2011年にLinkedInによって作成され、当初はメッセージングキューとして考えられていましたが、オープンソース化されて以来、本格的な分散イベントストリーミングプラットフォームへと急速に進化しています。
さて、上記の文はConfluent社のホームページから引用したものですが、Kafkaは、「分散イベントストリーミングプラットフォーム」であるという言葉の紐付けは出来ましたが、「分散イベントストリーミングプラットフォーム」とはいったい何をするためのプラットフォームなのでしょう。
もう少しわかり易くイメージをつけてもらうため、Apache KafkaのWebサイトから引用して、実際のユースケースをみてみましょう。
※ストリームとは、絶え間ない連続した流れの意味で、ストリームデータとは、急速に無限に発生し、絶えず流れているデータの事で、時間の経過によりデータ性質・傾向・価値が変動します。TwitterやInstagram等SNSのデータや、コンマ数秒単位で変動する証券取引所の株価のデータ(いわゆるビッグデータ)が代表例です。
どうでしょう?なんとなくイメージは湧いてきましたか?
様々なデータを収集して、分析する「ビッグデータ活用」は、どんな企業や組織にとっても重要になってきていますが、データを分析する手前の「データの下準備」で、技術的な壁に直面し、四苦八苦している企業や組織も多いのが現状です。「データの下準備」を制する者が「データ分析やデータ活用」を制するとも言われるほど、重要なポイントです。
技術的な壁とは、具体的にはどういう壁なのでしょうか?
もう少しブレイクダウンすると、
「メッセージキューイング」とは、異なるアプリケーションプログラム間で動作を連携させて、データを交換させる際の方式の一つ。送るデータを「キュー」と呼ばれるデータ領域に保持し、データを受ける側の処理が完了するのを待たずに次の処理へ移る方式。送信する側は、「キュー」にデータを置くだけで、送り先と同期できなくても確実にデータを送り届けることができる
大量のイベントデータの取込・保存・変換などの処理を、「リアルタイム」かつ「安全」に実施し、ビッグデータでもパフォーマンス良く処理できるよう「スケールアウト」する必要がある「リアルタイムストリーミングアプリケーションのシステム」を構築するため、Kafkaで「キューイング」を行う
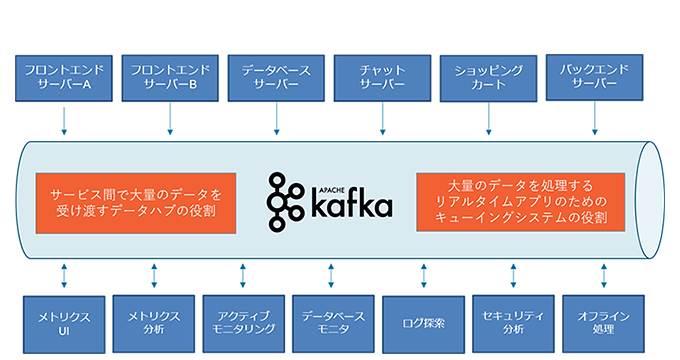
図4-1-1を例にみてみると、Kafkaがなければそれぞれのサーバーやアプリケーションから直接分析環境へログを送る必要があり、送るログも重複しそうです。また、連携するためには、膨大な開発やメンテナンスが必要です。
発生するイベント元が複数、それに伴い大量になればなるほど、システムは複雑になるため、きちんとしたデータパイプラインを構築する必要がありそうですね。
なんとなくKafkaの役割が見えてきましたか?
役割が見えてきたところで、以降では、Kafka誕生の背景からその必要性、基本機能の解説など、これからKafkaに入門する方のための基礎知識を紹介していきます。