Kinetica Kinetica 製品情報
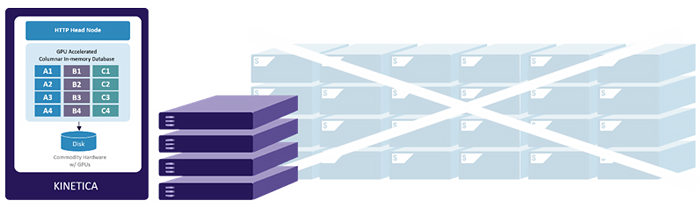
IBM Power System S822LC for HPC(通称”Minsky”)をはじめとした、NVIDIA DGX-1、HPE、Cisco、DellなどのさまざまなGPU搭載サーバープラットフォームやパブリッククラウドのGPUインスタンスで展開でき、データウェアハウスや高度な分析、ビジュアライゼーション、機械学習やディープラーニングなど、近年のビッグデータ分析に必要な機能を統合的に提供できる唯一のデータベース製品です。
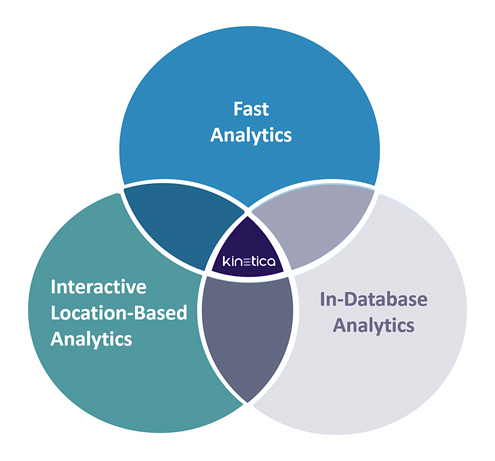
- Fast Analytics
- KineticaはGPUの並列処理の性質を利用するように設計されています。 大規模なデータセットに低レイテンシ、高性能の分析を提供し、ストリーミングデータをクエリでリアルタイムに利用できるようにします。
- In-Database Analytics
- データベース内から分散カスタムコンピューティングをダイレクトに行うことができます。 GPUサーバープラットフォーム上でデータベースを配置することによって、AIとBIをデータベースと同じプラットフォーム上で実行することが可能です。
- Interactive Location-based Analytics
- GPUリソースを使用したネイティブのビジュアライゼーションパイプラインにより、これまで難しかった大規模な地理空間データセットを高速に扱うことが容易になります。 IoTユースケースや地理空間アプリケーションなどのリアルタイムかつビジュアライズが必要なシステムのパフォーマンスを劇的に変えることができます。
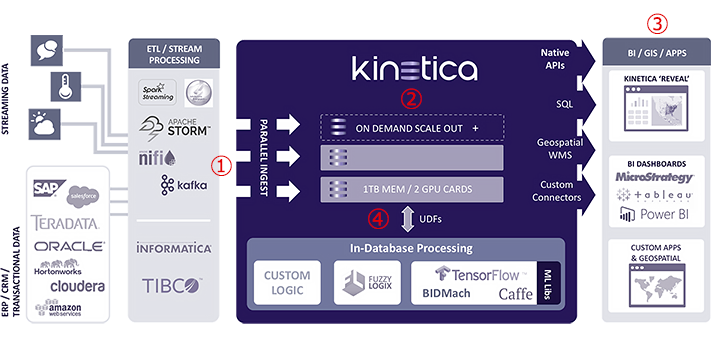
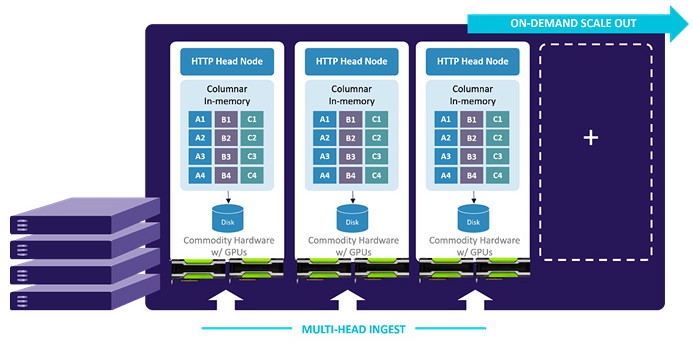
(1) 複数のソースからのインジェスト
Apache Kafka、Apache NiFi、Apache Spark、Spark Streaming、Apache Storm、およびODBC / JDBC用のあらかじめ構築されたコネクタにより、広範なデータソースからのデータを簡単に取り込むことができます。
(2) スケールアウト
Kineticaは、業界標準ハードウェア上で線形スケーラビリティを提供します。 高可用性のためにデータ複製が処理されます。 シャーディングは自動的に行うことも、ユーザーが指定して最適化することもできます。Kineticaは、分散型データベースとして基礎から構築され、データの取り込みとOLAPクエリの両方のパフォーマンスの要件とSLAを満たすために、水平または垂直に簡単に拡張できます。
Kineticaにデータを書き込んでいるクライアントまたはシステムは、クラスタ間でパラレル接続に自動的にルーティングされます。
OLAPクエリは、クラスタ全体で完全に分散されたGPUアクセラレーション処理を使用して実行されます。
(3) 包括的なAPI
Kineticaは、RESTful HTTPエンドポイント経由で簡単にやりとりできます。 JSONとAvroの両方のシリアル化をサポートします。 オープンソースのネイティブ言語バインディングは、Java、Python、Javascript、およびC ++で使用できます。
(4) データベース内処理による高度な分析
User Defined Function(UDF)は、データベース内での計算とデータ処理を可能にします。 Kineticaは、GPUの並列計算能力を完全に利用するデータベース上でこのような機能を独自に提供しています。また、TensorFlowやCaffeなどの機械学習ライブラリを利用してAIシステムとの統合が可能です。
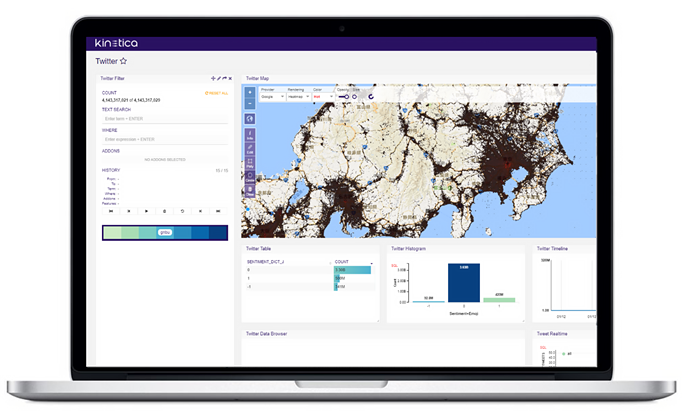
Kineticaの拡張可能で柔軟なビジュアライゼーションフレームワーク「Reveal」は、GPUで加速されたマップや付随するダッシュボードのレンダリングと組み合わせて、インタラクティブなリアルタイムデータの探索を可能にします。
Kinetica Revealを使用すると、ビジネスアナリストは、数十億のデータ要素を視覚化して即座に操作することで、より迅速な意思決定を行うことができます。
ユーザーはSQLを知る必要はありません。 データテーブルをドラッグ&ドロップするだけで、データをスライスアンドダイスしてオンザフライ解析を作成することができます。
わずか数回のマウスクリックでインタラクティブなリアルタイムダッシュボードを作成するためのダッシュボードを12種類以上用意しています。
Kinetica Revealには、高度なマッピング機能が含まれており、Google、ESRI、Mapbox、Bingなどの主要なマッピングプロバイダと統合され、膨大なデータセットに対してインタラクティブなロケーションベースの分析を実行できます。
Revealは、権限ベースのウィジェット、ビュー、およびダッシュボードのための、きめ細かなマルチレベルのアクセス制御によるセキュリティの強化も誇っています。
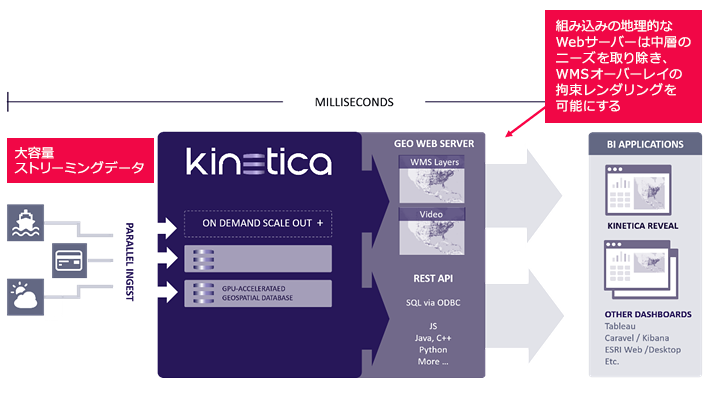
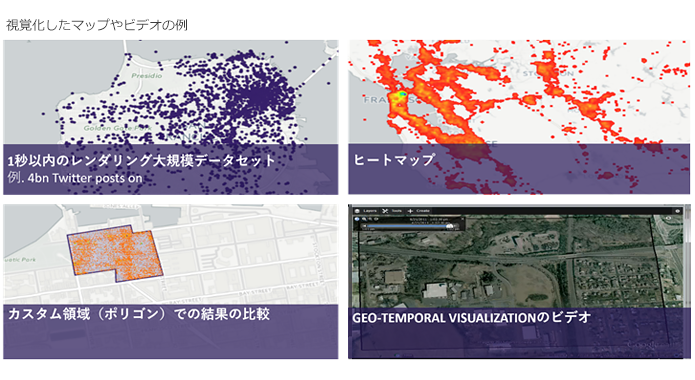
企業がOLAPから予測分析や機械学習に移行するにつれて、GPUの並列処理能力の恩恵を受ける企業が増えています。
大規模なデータセットで洗練された分析に低レイテンシの応答を必要とする組織にとって、Kineticaのデータベース内機能は、大幅に高速な操作に加えて、より多くのカスタマイズを提供します。
別々のシステムで動作する既存のカスタムコードは、Kineticaで動作するようにすばやく再構成できます。
UDFは、分析プラットフォーム内でプロセスを自動化し、ビジネス計算を実行するオプションの世界を開きます。
予測分析とより高度なデータサイエンス ワークロードでは、これらのより複雑な問題に取り組むことができるデータ・サイエンティストが担当する特殊なハイパフォーマンス・コンピューティング(HPC)システムにデータをエクスポートすることがしばしばありました。
これらのグループは、パフォーマンス上のメリットのためにGPUアクセラレーションを必要とします。
ディープラーニングのおアルゴリズムはCPUに比べてGPUで数倍高速で動作するため、学習時間は数週間から数時間、または数時間から数分に短縮できます。
このようなアルゴリズムを調整し、訓練し、繰り返し時間を追加する必要があるため、このパフォーマンスの向上は非常に重要です。
このような特殊なシステムにデータを移動するのは面倒で時間がかかるため、データサイエンスをビジネスから切り離すことは一般的であり、モデルを本番運用に戻すことは容易ではありません。

UDFを使用すると、GPUで高速化されたデータサイエンスロジックとカスタムコードを使用して、単一のデータベースプラットフォーム上で高度なビジネス分析を実行できます。 このようなデータベース内処理機能が、分散プラットフォーム上のGPUの並列計算能力を完全に利用するデータベース上で利用可能になったのは初めてのことです。
Kineticaのデータベース内処理は、高度なコンピューティング・ツー・グリッド分析を行うための非常に柔軟な手段を提供します。
この業界初の機能は、データサイエンスを民主化するのに役立ちます。 これまで、組織は通常、機械学習や深い学習などのデータサイエンスワークロードのGPUアクセラレーションを利用するために、特殊な環境にデータを抽出する必要がありました。
Kineticaは、洗練されたデータサイエンスワークロードを展開し、ビジネスアナリティクスに使用されているのと同じデータベースで利用できるようになりました。